arss -g 1 -s -min 27.5 -max 20000 -r 44100 -f 16 -p 100 ifft.bmp ifft.wav
À l’écoute du son généré, on constate immédiatement certains motifs qui sont répétés, on en vient donc à une des parties de l’émission, la reconnaissance de formes à partir du son.
On peut essayer avec un alphabet et une police avec serif, cette fois on
utilisera le flag -l afin d’obtenir une échelle de fréquence linéaire.
En regardant le spectrogramme correspondant au fichier audio, on
retrouve bien nos lettres. L’image a été générée à l’aide de
Ceres3.
 Fichier OGG
Fichier OGG 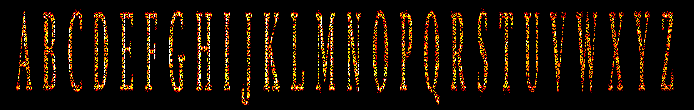
Avec un peu d’entraînement, on distingue plutôt bien les différentes lettres les unes des autres. Après quelques essais avec du braille, il est un peu difficile de faire la distinction dès que plus de 3 sons sont mélangés. Il faudrait un peut être un autre type d’encodage.
On peut reconnaître des formes simples :  Fichier
OGG
Fichier
OGG
Ou des paysages (les images proviennent de Flickr :
1
2),
qui ont été traîtés dans Gimp avec les outils de
détection de contour (dans ce cas là « Edge »):  Fichier OGG (Paysage 1)
Fichier OGG (Paysage 1)  Fichier OGG
(Paysage 2)
Fichier OGG
(Paysage 2)
On peut réaliser assez vite des échantillons complexes avec des effets
graphiques (ici le plugin Qbist de Gimp) :  Fichier
OGG
Fichier
OGG
On peut écouter des données extraites d’un spectromètre de masse
(intensité de 5 ions d’un extrait de sarments de vigne en HPLC-MS) :
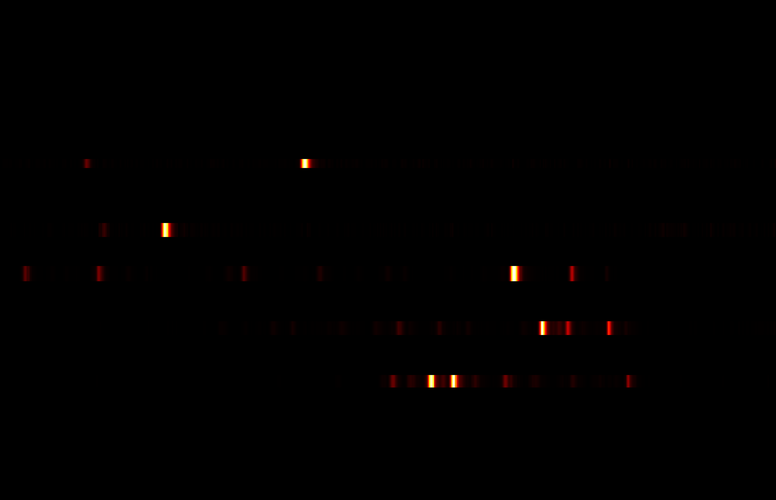 Fichier OGG
Fichier OGG
Sinon quelques musiciens se sont amusés avec ça (Aphex Twin, Plaid, Venetian Snares, NIN…): Bastwood, The best thing I learned today, Twisted sifter
Une boîte, SeeingWithSound commercialise des lunettes utilisant ce principe pour permettre aux aveugles de percevoir ce qu’il y a en face d’eux.