NAPRALERT is a leading database containing >40 years of the natural products literature.
NAPRALERT
NAPRALERT, acronym of NAtural PRoducts ALERT, is a database created at UIC in 1975 by the late Norman R. Farnsworth. The database aims at being a systematic and curated database of all the research related to Natural Products and Pharmacognosy in general. It includes but is not limited to the coverage of:
- Traditional use of plants and Natural Products
- Distribution of compounds produced/present in organisms
- Distribution of organisms producing/presenting a compound
- Biological assays in-vitro and in-vivo of organisms, extracts or purified compounds
With its thousands of users and more than 200,000 scientific papers manually annotated, NAPRALERT is a unique trove of information.
My role
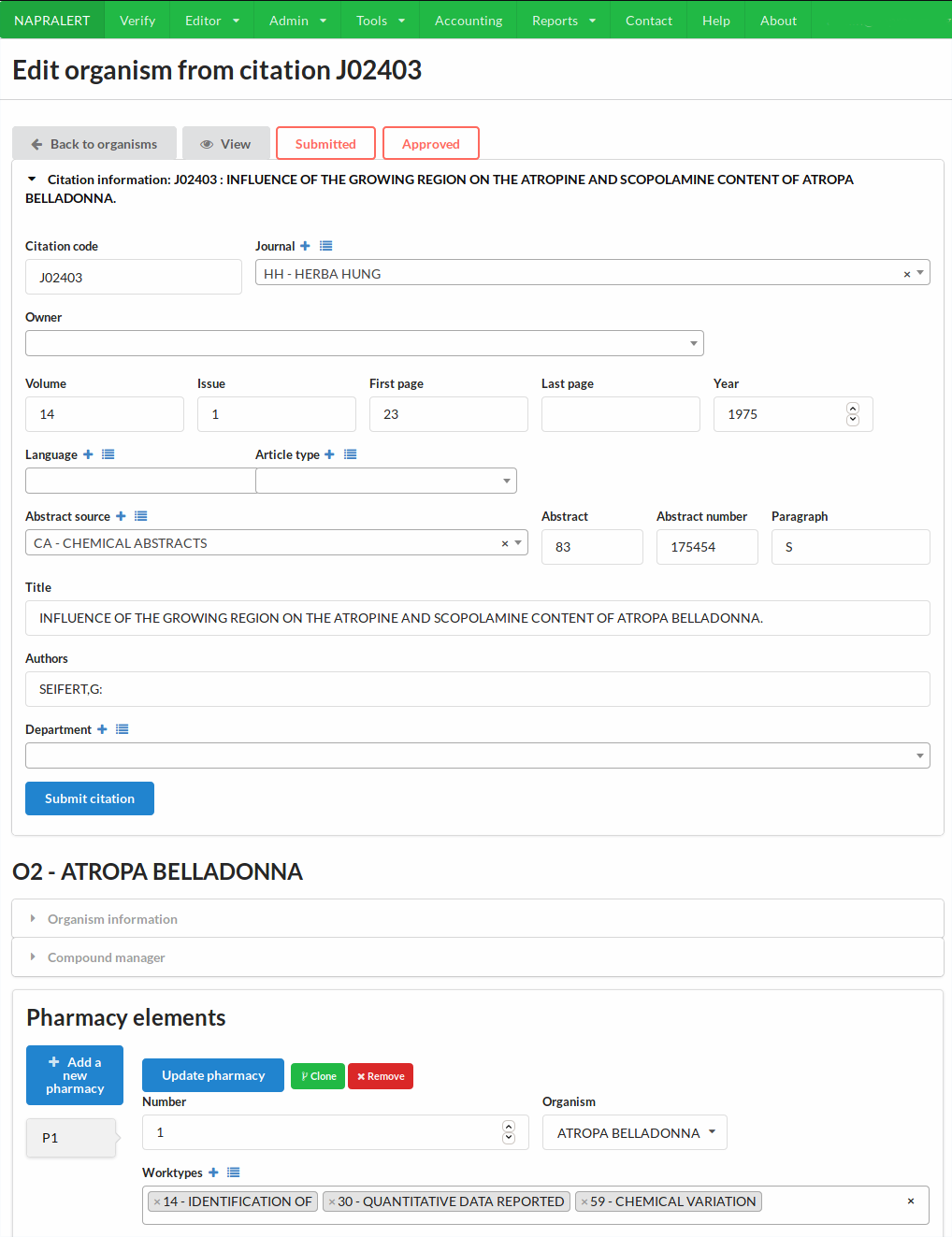
The database was running until 2015 on an aging IT infrastructure that was both costly and difficult to maintain and enhance. This is why Guido Pauli recently appointed director of NAPRALERT, James Graham, its current editor, and I decided that it would greatly benefit from a complete rewrite.
When I was given this project, it was running as a .NET application querying a MSSQL database on a contractor’s premises. As the cost of maintaining this resource was prohibitive and reduced our abilities to make it evolve, it was decided to upgrade it.
As the application is mostly a simple CRUD with advanced data-entry (autocompletion, multiple-level of data) and advanced queries, I decided to investigate Ruby On Rails. But after the initial prototype, I decided to go back to a Django-based system as it proved to be much more efficient for the task at hand (to be fair, I knew much more Python than Ruby).
My role was really wide in that project (all of that took around 9 months not full-time):
- Choose a back-end framework
- Choose the database
- Convert the data from MSSQL to the selected database
- Make sense of how the data was stored, this part is pretty interesting there are a lot of idiosyncrasies. I realized that the Conway’s law really apply.
- Work with the internal users for a new data-entry approach
- Write the new application
- Write the UI
- Order the infrastructure
- Configure and secure it
- Work with the network teams of the university to get our server public facing and get a SMTP server our system can talk to.
Starting in January 2015 and until August 2015, I wrote the new NAPRALERT from scratch using the most Free (as in Free Speech) technologies I was more familiar with:
- Python, as a programming language.
- PostgreSQL, as a database engine.
- GNU/Linux, for everything. For the details, the most critical parts are running Debian GNU/Linux.
- Qemu, for running Virtual Machines.
- NGINX, as a web server.
During that journey, I learned or improved with a lot of other tools and technologies:
- Ansible, for the easy deployment and test. (thanks kuroishi for introducing me to it)
- Packer, for creating new Virtual Machines in a reliable manner. (thanks hef for introducing me to it)
- Docker, for creating easy to toss containers and spinning up instances quickly.
- Django, as a web framework. (thanks Carl and Sheila for showing me the way)
- Django autocomplete-light, as an autocomplete solution that really works.
- Celery, as a task queuing and scheduling system.
- Semantic UI, as a really nice and easy to use web UI interface.
- Gunicorn, as a pre-forker reducing load and allowing way better response times (yes now we can handle 1000 times more than our average user charge…)
- And many other things that would be too long to list.
Where it is now
The service went public on October 2015, and is now happilly serving thousands of users. There is still a lot to do now that we have a nice and shiny new platform to bring all the nice ideas that we compiled. Currently it mostly gets security and admin-side feature upgrades, as most of our resources are focused on the next project that could make this one obsolete.
You can find an example of what can be done with it in my academic profile.
What is its future
Currently, I am working on a different project that should both complement and embrace NAPRALERT. It is based on a new ontology, the Pharmacognosy Ontology, connected to existing ontologies and with a text-mining component based on word-embedding and bayesian models. The idea is to pre-annotate the literature to reduce the burden for our data-entry people. But more on that later as it will benefit from a few pages by itself.